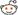
Fatdog64 902 Final Is Released
Fatdog64 902 Final Release.Forum announcement.
You can download it from ibiblio.org, uoc.gr, or nluug.nl.
No comments - Edit - Delete
Fatdog64 901 Final Is Released
Fatdog64 901 Final Release.Forum announcement.
You can download it from ibiblio.org, uoc.gr, or nluug.nl.
No comments - Edit - Delete
Fatdog64 900 Final is released
Fatdog64 900 Final Release.Forum announcement.
You can download it from ibiblio.org, uoc.gr, or nluug.nl.
No comments - Edit - Delete
Fatdog 900 Beta is released
Fatdog 900 marches along, and now the Beta release is here.Fatdog64 900 Beta Release.
Forum announcement.
You can download it from ibiblio.org, uoc.gr, or nluug.nl.
No comments - Edit - Delete
Fatdog 900 Alpha and Fatdog 814 Simultaneous Release
The long awaited release of Fatdog64 900 is now here. It is in alpha state. At the same time, we release the last, and final version of the 800 series (814).Fatdog64 900 Alpha Release.
Fatdog64 814 Final Release.
Forum announcement.
You can download 900 Alpha from ibiblio.org, uoc.gr, or nluug.nl.
And 814 Final from ibiblio.org, uoc.gr, or nluug.nl.
No comments - Edit - Delete
Fatdog64 813 is released
Release notes here, announcement (and discussions) here.Get it from the usual mirrors: ibiblio.org, uoc.gr, or nluug.nl.
No comments - Edit - Delete
Who fact-checks the fact-checkers?
In the moment of confusion, who is the arbiter of truth?Who appoints the arbiter of truth?
Or shall we speak in one voice with Pilate, who asked: "What is truth?" (John 18:38).
No comments - Edit - Delete
The Pale Blue Dot
Image of our homeworld taken from a distance of 6 billion kilometres away (approximately, 40.4 AU, or 5.5 light-hours), by Voyager 1, on 14 Feb 1990.For context, at this location, Voyager was farther than the average orbital distance of Pluto.
This is what Carl Sagan had to say about the image:
Look again at that dot. That's here. That's home. That's us. On it everyone you love, everyone you know, everyone you ever heard of, every human being who ever was, lived out their lives. The aggregate of our joy and suffering, thousands of confident religions, ideologies, and economic doctrines, every hunter and forager, every hero and coward, every creator and destroyer of civilization, every king and peasant, every young couple in love, every mother and father, hopeful child, inventor and explorer, every teacher of morals, every corrupt politician, every "superstar," every "supreme leader," every saint and sinner in the history of our species lived there--on a mote of dust suspended in a sunbeam.
The Earth is a very small stage in a vast cosmic arena. Think of the rivers of blood spilled by all those generals and emperors so that, in glory and triumph, they could become the momentary masters of a fraction of a dot. Think of the endless cruelties visited by the inhabitants of one corner of this pixel on the scarcely distinguishable inhabitants of some other corner, how frequent their misunderstandings, how eager they are to kill one another, how fervent their hatreds.
Our posturings, our imagined self-importance, the delusion that we have some privileged position in the Universe, are challenged by this point of pale light. Our planet is a lonely speck in the great enveloping cosmic dark. In our obscurity, in all this vastness, there is no hint that help will come from elsewhere to save us from ourselves.
The Earth is the only world known so far to harbor life. There is nowhere else, at least in the near future, to which our species could migrate. Visit, yes. Settle, not yet. Like it or not, for the moment the Earth is where we make our stand.
It has been said that astronomy is a humbling and character-building experience. There is perhaps no better demonstration of the folly of human conceits than this distant image of our tiny world. To me, it underscores our responsibility to deal more kindly with one another, and to preserve and cherish the pale blue dot, the only home we've ever known.
Both the image and the quote were sourced from Wikipedia. I added the arrow to point out the location of the pale blue dot. Yes, it's that small. In fact, according to NASA, it is less than a pixel.
No comments - Edit - Delete
How to handle bug report
I recently tested the Go language (a language invented by a star-studded team, including the original inventor of C language and Unix), however, it didn't go smoothly.I encountered a problem: I cannot compile a simple hello world program. It gave out a cryptic error message which search engines of the world cannot find.
Concerned, I raised a bug report. Mind you, it's not a support request, not a question. It's a __BUG REPORT__.
I received two kind of responses.
(1) The first one was short and sweet, and closed the ticket immediately, basically telling me not to ask question there.
But I wasn't asking a question. I was reporting what I thought to be a BUG!
This very unhelpful response was a big turn off. How would you encourage people to use your product if you ignore bug reports on your public bug tracker?
I quickly replied that with a piece of my mind.
My retort attracted a second response.
(2) This second response was a lot more helpful. It gently informed me that this was probably the problem of my own making; it linked to another ticket which had similar symptoms to the one I reported, and showed me how my issue could be caused by the same problem as described in the other ticket.
This response motivated me to do more investigation, and it turned out that the problem was indeed on my side. Hence, I replied in kind and moved on, after thanking the second responder.
No cookie for correctly guessing which one wins another customer (if this were a commercial project).
______________
So what's the outtake here?
With response (2): I learn that Go uses files with the name of .a that aren't libraries, and therefore should not be stripped.
But more importantly, others will learn the same thing (once the issue is indexed by search engines, next time someone else tries looking it up, they won't find empty results).
And finally, perhaps, just perhaps, the Go developers themselves will learn that adopting a file extension (.a) that already has an existing, different meaning, is probably not the best idea.
What do we learn from response (1)? Go away, and Go use another language.
___________
Sadly, attitude like (1) is very common on the IT world - especially in the commercial world. (I know Go isn't commercial, but I'm willing to bet that most of its core developers and support persons are employees).
Read the whole saga yourself: https://github.com/golang/go/issues/50509
No comments - Edit - Delete
Xdialog ported to GTK+ 3
Xdialog is a popular program to create a simple GUI for shell scripts. It is easy to use and implements the most commonly used GUI elements (e.g. input boxes, message boxes, etc). It was one of the earliest program of its kind.Sure, there are tons of similar program like this nowadays, some with even more powerful features - kdialog, zenity, yad, and I'm sure there are a lot more ... but Xdialog has two things going for it.
1. It's available almost anywhere.
2. It's command line interface (the parameters you pass to it, to get the GUI you want), is stable and unchanged in the last 20 years.
Any program you write with Xdialog would most probably work, while the same thing can't be easily said for the others.
There is only one problem. Xdialog is old, and for the longest time, has always been available only with those with GTK+ 2. GTK+2 has been end-of-life for about a decade now, although it is still popular.
GTK+ 2 replacement is GTK+ 3, so it's a reasonable migration path (as opposed to Qt for example, which requires a total re-write).
So far, I have not found a port of Xdialog to GTK+ 3, so I decided to start my own. The motivation is simple: so that in the future when we move to GTK+ 2-less future (only pure GTK+ 3), existing shell scripts that use Xdialog still works (we have a ton of those).
The result is here: http://chiselapp.com/user/jamesbond/repository/xdialog/index
The code in the repository compiles with both GTK+ 2 and GTK+ 3 (the original Xdialog compiles with GTK+ 1 and GTK+ 2). Login as anonymous in order to download the tarball. The port retains almost all of the features of the original Xdialog (except "unavailable" status are not available for radiolist/checklist/buidlist).
PS: While in the process of porting it, I found that somebody already did that here: https://github.com/wdlkmpx/Xdialog. I ended up using borrowing some of the codes from there to speed up the porting process, although the final code that goes into my repository is different wdlkmpx's. Another thing which is different is that I tried to retain all the existing functionalities, while wdlkmpx's port has dropped some of the lesser used features (which he documented in the his version of the Xdialog's manual).
No comments - Edit - Delete

